Dataset Overview
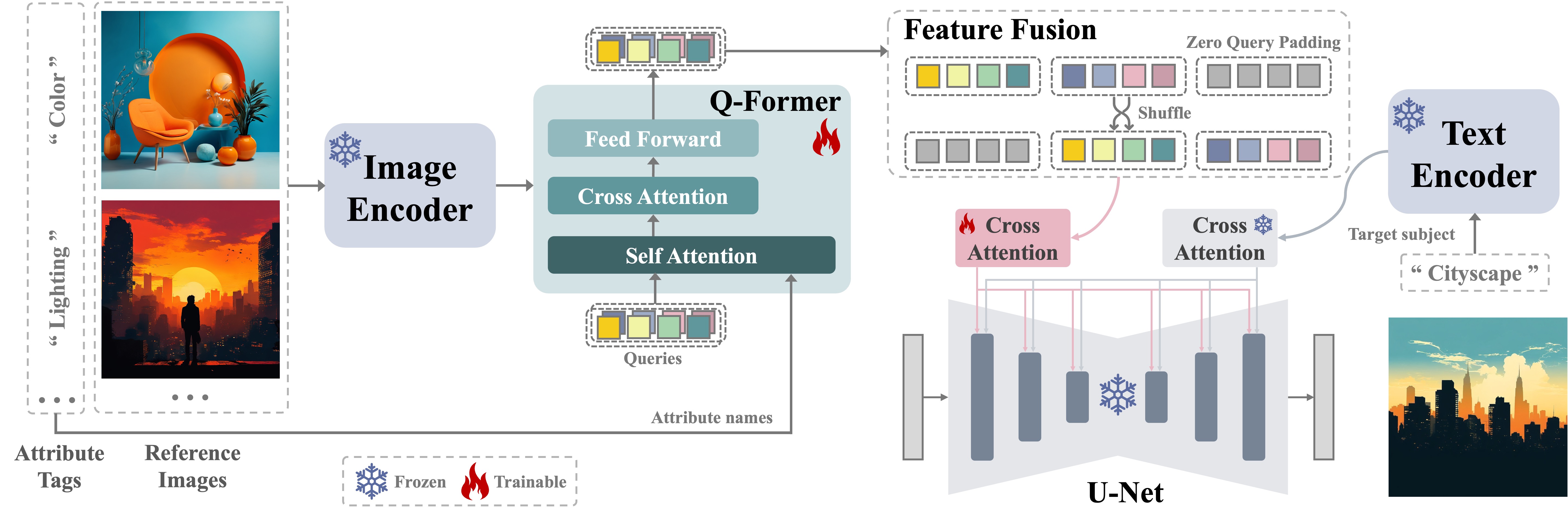
Visual Attributes Taxonomy and Paired Data Construction
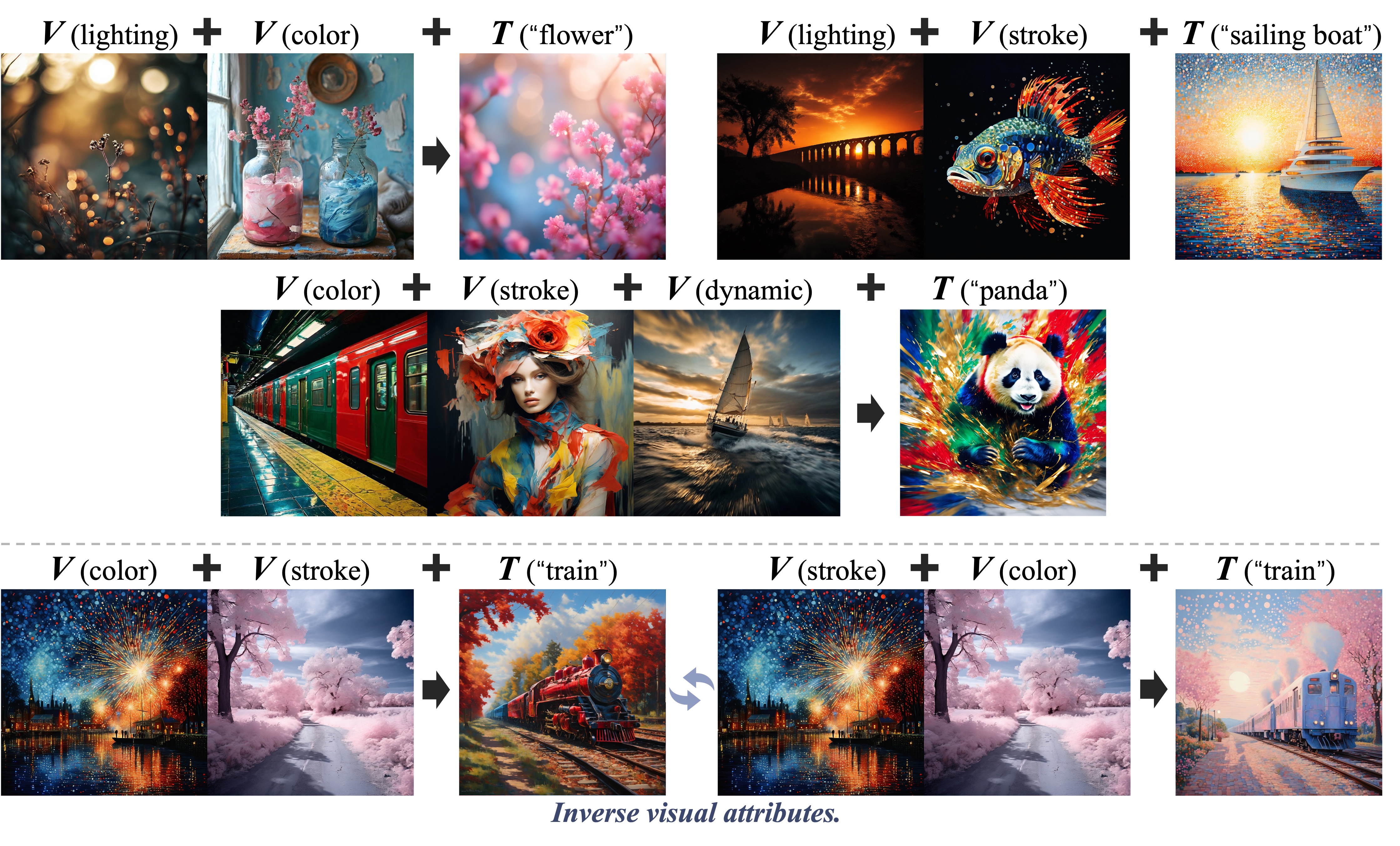
Visual attributes encompass a broad spectrum, varying across use cases. To address this, we identified general attribute types to cover diverse applications, categorizing them into groups and refining each into detailed subcategories. Redundant or unreasonable entries were filtered out. Similarly, we developed a taxonomy for subjects. Attributes and their augmentations were then paired with specific subjects to generate prompts using a state-of-the-art image generation model, enabling easy pairing of images with shared attributes. Finally, pair accuracy was validated through human evaluation, incorporating a range-sensitive filter introduced below.
It is worth noting that data constructed using this method does not guarantee precise physical or pixel-level pairing but only ensures rough consistency. Nevertheless, it enables large-scale data construction and supports most customization needs.
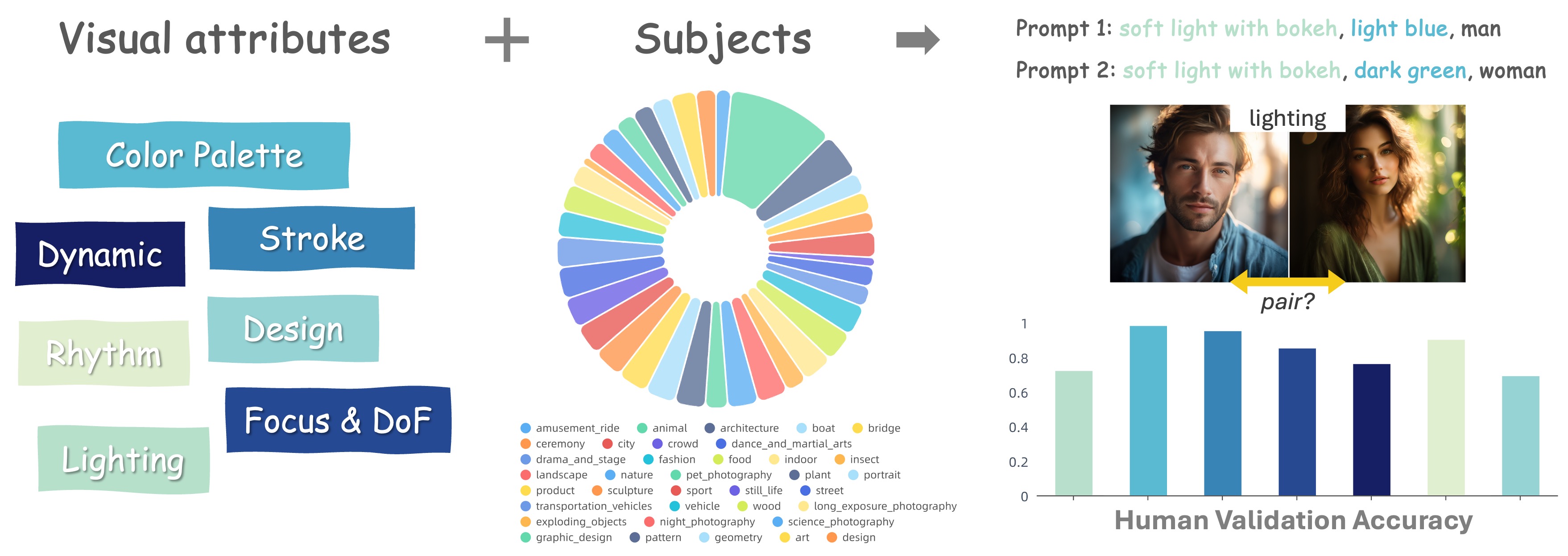
Range-sensitive Data Filtering
Not all generated images with the same attribute exhibit similar visual effects. For example, attributes like "color" and "stroke" transfer easily across different subjects, while others, such as "lighting" and "dynamics," are range-sensitive, producing varying effects depending on the subject's domain. We use powerful multimodal large language models like GPT-4 to automatically define an attribute's application range, ensuring greater visual consistency between images within that range.